

Deep learning is a computational technique that allows you to extract and transform data from sources such as human speech or image classification, using multiple layers of neural networks. Each of these layers takes its inputs from the previous layers and refines them, so progressively. The layers are trained by algorithms that minimize their errors and improve their accuracy. In this way the networks learn to perform specific tasks.


Areas of application
Deep learning is a powerful, flexible and above all simple tool. This is why it is applied in many disciplines. These include both the physical and social sciences, or medicine, finance, scientific research and more.
Here is a list of some disciplines that use deep learning:
- Natural Language Processing (NLP). Deep learning has proven to be able to recognize spoken words (speech recognition) and is also particularly effective in the treatment of written documentation. It is in fact able to search for names, concepts and data within thousands of articles and various documents.
- Computer vision. Deep learning has laid the foundation for image interpretation, particularly in facial recognition, and in solving problems such as locating vehicles and pedestrians from webcam images.
- Medicina. Deep learning is able to analyze diagnostic images and learn the recognition of any anomalies. Furthermore, it can learn from physiological characteristics the discovery of pathologies.
- Biologia. Deep learning is coming back very useful in protein classification, genomics, cell classification, and analysis of protein-protein interactions
- Generazioni di immagini: Deep learning is able to modify images in an intelligent way, with complex operations such as coloring images in black and white, increasing the resolution of images, removing noise from images, and knowing how to compose artistic works using the styles of famous artists starting from basic images.
- Ricerca Web:web search engines make use of deep learning.
- Giochi: more and more games make use of artificial intelligence, to improve strategy and simulate human behavior in artificial opponents.
- Robotica: Deep learning is finding applications in the computation of the trajectories and dynamics of complex robotic systems for manipulating objects.
At the basis of deep learning: neural networks
At the base of Deep Learning are neural networks. Although they were devised in the immediate postwar period, several decades passed before neural networks could be considered useful in any way. In fact, for a long time they were neglected because they were seen as a simple mathematical model. Neural networks took on practical value only recently, thanks to the gradual improvement of computers and the advancement of information technology.
Furthermore, the artificial model of a single neuron (perceptron) is not able to highlight forms of learning. What we are able to do when using different layers of neurons, connected in certain ways to each other. These complex and structured models are neural networks.
The transition from a single-perceptron model to their own network of layered interconnections with certain thresholds and signal additions, required over 30 years of study. A development favored only in their ability to achieve thanks to the advancement of the computing capabilities of the new processors.
And from neural networks, Deep Learning is born, which has now become a real scientific discipline.
The history of the Neural Networks
The first insight into the possibility of creating a neuron model dates back to 1943, and is due to Warren McCulloch, a neurophysiologist, and Walter Pitts, a logician. Both worked on the development of a mathematical model of an artificial neuron. Based on studies of the functioning of real neurons, they intuited that the model could be built using simple additions and thresholds.

From a practical point of view, it can instead be said that the real father of the artificial neuron was Rosenblatt. In fact he developed in 1957, based on the mathematical model of McCulloch and Pitts, a device, the Mark I Perceptron. In his famous article The Design of an Intelligent Automaton Rosenblatt wrote: “We are now about to witness the birth of such a machine –- a machine capable of perceiving, recognizing and identifying its surroundings without any human training or control.”


The perceptrone who made Rosenblatt was able to successfully recognize simple figures. Shortly thereafter, Marvin Minsky, an MIT professor, in his book Perceptrons (MIT Press), expounded various studies on these objects, showing that a single layer of perceptrons could not learn simple mathematical functions, which they were able to make multiple layers (neural networks).
Unfortunately, the global academic community was not in the least impressed by this discovery, remaining uninterested in the subject in general and leaving it in limbo for over 30 years.
It was only with the advent of computer science and new computers that in the 80s and 90s Minsky’s studies were resumed for the realization of real and practical projects. Unfortunately, even in those years, technology led to the development of multi-layered neural networks (which were capable of doing useful work) too slow and large to have a practical impact.
Another 30 years have passed since then and each advance in information technology and computing power has led to an evident improvement in neural networks, with the consequent realization of practical projects. And that’s how Deep Learning developed. Now we finally have what Rosenblatt promised at the time: “a machine capable of perceiving, recognizing, and identifying its surroundings without any human training or control.“
From neural networks to Deep Learning
From artificial neural networks to Deep Learning there is a fundamental step. Single artificial neurons connected together to become a neural network do not do Deep Learning. In fact, not all artificial neural networks are capable of Deep Learning. The networks must be “Deep” that is, they must be structured with many hidden layers, and not all deep learning architectures are neural networks.

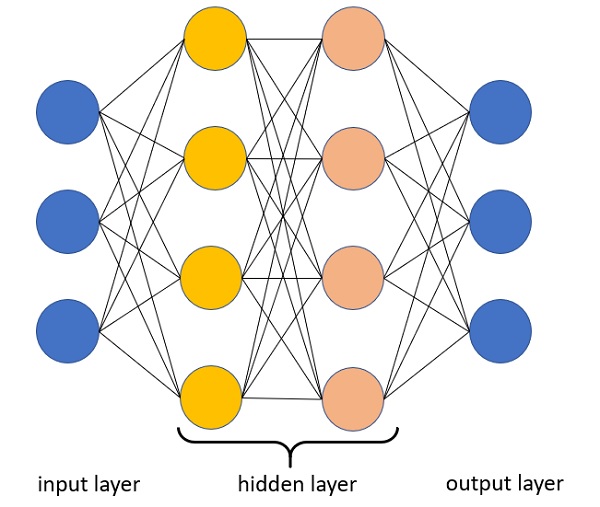
In fact, Deep Learning exploits the different layers of neural networks to carry out multiple levels of representation and abstraction, passing from layer to layer.
Each layer or level of the neural network corresponds to a distinct level of concepts, where higher level concepts are defined by the lower levels, to be elaborated and converted to increasingly abstract concepts in the upper layers.
It is therefore a set of algorithms that uses artificial neural networks to learn how to break down complex data such as images, sounds and text into different levels of abstraction.
The Deep Learning architectures
One of the great potential of neural networks is that they can be structured in infinite ways. In recent years, many types of interconnections between artificial neurons, called architectures, have developed. Each of them has been studied and has peculiar learning characteristics that make them specific for certain applications.
Here are some examples:
- Deep Neural Networks
- Deep Belief Networks
- Convolutional Neural Networks
- Convolutional Deep Belief Networks
- Deep Boltzmann Machines
- Stacked Auto Encoders
- Deep Stacking Networks
- Tensor Deep Stacking Networks (T-DSN)
- Spike-and-Slab RBMs
- Compoung Hierarchical-Deep Models
- Deep Coding Networks and Deep Kernel Machines
Deep Learning Software
One of the fundamental aspects for the development and success of Deep Learning in the last 10 years is the fact that there are brand new applications capable of providing all the necessary tools to set up neural network architectures and study them.
Here are some of those currently available.
- Neural Designer
- H2O.ai
- DeepLearningKit
- Microsoft Cognitive Toolkit
- Keras
- ConvNetJS
- Torch
- Deeplearning4j
- Gensim
- Apache SINGA
- Caffe
- Theano
- ND4J
- MXNet