Introduzione
Questo articolo è tratto da un bellissimo post di Eben Upton . Di recente si è discusso molto riguardo ad alcune vulnerabilità nella sicurezza riscontrate in molti processori, denominate Spectre e Meltdown. Moltissimi sono i processori che sono risultati vulnerabili a questi attacchi tra cui molti processori della Intel, della AMD e anche alcuni core ARM.
Upton ha voluto scrivere un bellissimo articolo in cui spiega come tutti i modelli Raspberry Pi siano immuni a questa vulnerabilità. Ho cercato di riassumere in grosse linee quello che dice l’articolo, altrimenti potete leggere tranquillamente quello originale (in inglese)
Spectre e Meltdown
Questo nuovo genere di vulnerabilità sfrutta alcuni difetti, o meglio, ‘buchi’ nell’architettura del processore, inevitabili quando le architetture diventano via via sempre più complesse. Infatti nel tentativo di rendere sempre più efficienti i processori superando quelli che sono i limiti di una architettura, si devono creare dei meccanismi sempre più complessi. Questi meccanismi possono riscontrare nel tempo delle “carenze” logiche nei controlli, dato che nel passaggio logico a quello reale è impossibile tenere conto di tutte le occorrenze possibili.
In questo caso, particolari innovazioni apportate ai meccanismi di elaborazione dei processori, come il caching e l’esecuzione speculativa, che hanno portato enormi incrementi nelle prestazioni dei processori, hanno introdotto anche delle vulnerabilità. Queste due tipologie di vulnerabilità sono state denominate Spectre e Meltdown.

Spectre è stato scoperto dai ricercatori da una serie di ricercatori ed è stato reso pubblico, insieme a Meltdown, il 3 gennaio del 2018. Spectre è in grado di forzare i programmi in esecuzione ad accedere a locazioni di memoria che in teoria dovrebbero essere inaccessibili al programma, bypassando in maniera molto astuta i controlli interni al processore.
Meltdown è sempre basato su una vulnerabilità dei processori ma utilizza i sistemi operativi (tutti inclusi) sfruttando il meccansimo della corsa critica delle CPU tra le varie istruzioni che accedono alla memoria. Anche Meltdown permette di leggere i dati da una posizione arbitraria nello spazio degli indirizzi del kernel del sistema operativo.
Anche le schede Raspberry Pi sono vulnerabili a Spectre e Meltdown?
La risposta è bella quanto semplice. Fortunatamente, nessuna scheda Raspberry Pi è suscettibile a queste vulnerabilità, per via dei particolari ARM core che utilizzano.
Ma per comprendere al meglio cosa siano Spectre e Meltdown e su quali meccanismi vengano da esse sfruttati all’interno del processore, è necessario fare una serie di esempi su ogni meccanismo coinvolto in maniera molto semplice e riassuntiva.
A tale proposito, baseremo tutto l’esempio su un esempio che comprende una sequenza di 6 istruzioni: delle semplici espressioni con variabili.
t = a+b u = c+d v = e+f w = v+g x = h+i y = j+k
Per chi volesse approfondire l’argomento su come è progettato un processore, quali sono le varie architetture attuali su cui si basano ed i meccanismi al loro interno, non esiste miglior libro che Computer Architecture: A Quantitative Approach di Hennessy e Patterson (vedi sotto).
| Computer Architecture: A Quantitative Approach |
Adesso daremo alcune descrizioni sulle classi di processori utili per comprendere il loro meccanismo interno.
I processori scalari
La tipologia più semplice di processore moderno esegue un’istruzione per ciclo. Questo viene chiamato processore scalare. L’esempio della sequenza di istruzioni che abbiamo scritto sopra richiederà 6 cicli per poter essere eseguito da un processore scalare, essendo 6 le istruzioni riportate.
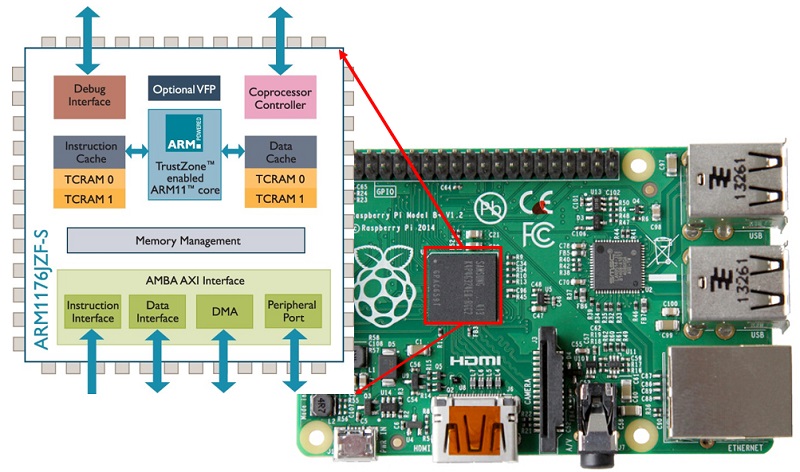
Esempi di questi processori scalari li ritroviamo nel 486 dell’Intel e nel core ARM1176 utilizzato sia in Raspberry Pi 1 che Raspberry Pi Zero.
I processori superscalari
Il modo più ovvio per rendere più veloce un processore scalare è certametne quello di renderlo più veloce, incrementando il suo clock speed. Comunque operando in questo modo, si raggiungono presto i limiti imposti da quanto veloci possono andare i logic gate all’interno del processore. Quindi i progettisti dovranno trovare altre soluzioni.
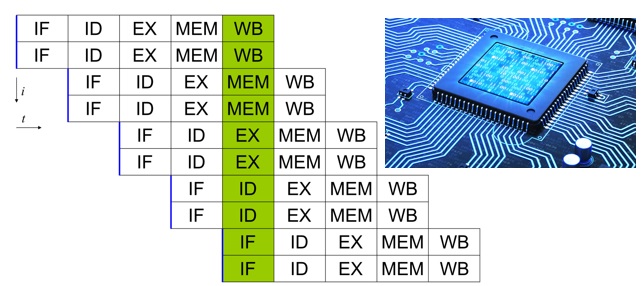
Un processore superscalare esamina il flusso di istruzioni in entrata e prova ad eseguirle diverse di esse contemporaneamente, sfruttando diverse pipeline (pipes), che però saranno soggette ad eventuali dipendenze tra le varie istruzioni. Le dipendenze sono dei fattori importanti di cui tenere conto.
Infatti un processore superscalare a due vie, teoricamente potrebbe accoppiare le sei istruzioni dell’esempio in una sequenza di tre coppie di istruzioni.
t, u = a+b, c+d v, w = e+f, v+g x, y = h+i, j+k
Ma questo non gioverebbe affatto. Infatti se diamo un’occhiata alla seconda coppia di istruzioni, noteremo che sarà necessario dapprima calcolare v per poter poi calcolare w. Ecco qui che esiste una dipendenza tra le due istruzioni e quindi la seconda coppia di istruzioni non può essere eseguita contemporaneamente.
Un processore superscalare a due vie quindi potrà eseguire le istruzioni sopra riportate in 4 cicli. Nel secondo ciclo e nel quarto ciclo, uno dei due pipe rimarrà vuoto
t, u = a+b, c+d v = e+f # second pipe does nothing here w, x = v+g, h+i y = j+k
Esempi di processori superscalari includono Intel Pentium, e i core ARM Cortex-A7 (Raspberry Pi 2) e ARM Cortex-A53 (Raspberry Pi 3).


I processori superscalari out-of-order
Ritornando all’esempio, si può vedere che se esiste una dipendenza tra due variabili, come v e w, allora si potrebbe sfruttare un’altra serie di istruzioni dipendenti, di cui una potrebbe essere potenzialmente utilizzata per riempire la seconda pipe rimasta vuota.
Un processore out-of-order è in grado di modificare l’ordine delle istruzioni in entrata allo scopo di riempire sempre tutte le pipe. Nel nostro esempio, invertendo le definizioni di w e x nella sequenza:
t = a+b u = c+d v = e+f x = h+i w = v+g y = j+k
avremo la possibilità di eseguire tutte le istruzioni in soli 3 cicli.
t, u = a+b, c+d v, x = e+f, h+i w, y = v+g, j+k
Esempi di processori out-of-order includono l’Intel Pentiun 2 e successivi e i processori AMD x86, e molti core ARM cone Cortex-A9, -A15, -A17, e -A57.
Branch prediction
L’esempio che abbiamo utilizzato finora è una parte di codice con una sequenza lineare di istruzioni. In realtà i programmi non sono in questo modo, infatti esistono delle possibili ramificazioni (branches) nella sequenza delle istruzioni . Per esempio ogni volta che in un codice è presente l’istruzione if si ha una ramificazione della sequenza di istruzioni. Queste ramificazioni possono essere incondizionate (vengono sempre eseguite) o condizionate (vengono eseguite a seconda di alcuni valori). Inoltre queste ramificazioni possono essere dirette (specificando in modo esplicito un indirizzo target) o indirette ( l’indirizzo target viene preso da un registro o una locazione di memoria dinamica).

Mentre recupera le istruzioni da eseguire, un processore può incontrare una ramificazione condizionata (conditional branch) che dipende da un valore che deve essere ancora calcolato. Per evitare una situazione di stallo, il processore deve indovinare quale sarà la successiva istruzione da recuperare: la prossima seguendo l’ordine in memoria (corrispondente ad una ramificazione non intrapresa) o a quella del branch target (corrispondente alla ramificazione intrapresa). Un branch predictor aiuta il processore a fare supposizioni intelligenti su quale ramificazione è stata presa o meno. Questa operazione viene eseguita raccogliendo delle statistiche su quanto spesso queste ramificazioni sono state prese nel passato.
I branch predictors moderni sono estremamente sofisticati e possono generare delle predizioni molto accurate. Le prestazioni elevate di Raspberry Pi 3 rispetto a Raspberry Pi 2 (molto più di quelle attese del 33%) sono in gran parte dovute alla differenza dei branch predictors utilizzati tra i processori Cortex-A7 e Cortex-A53.
Comunque, un malintenzionato, potrebbe essere in grado di far eseguire una studiata sequenza di ramificazioni, che portino ad una cattivo training del branch predictor, portandolo poi a fare pessime predizioni.
Speculative execution
Riordinare le istruzioni sequenzialmente è un modo potente per recuperare il parallelismo a livello delle istruzioni, ma come i processori diventano più larghi (cioè in grado di eseguire tre o quattro istruzioni), diventa sempre più difficile mantenere tutte le pipe occupate. I processori moderni hanno quindi incrementato la loro capacità di ipotizzare (speculate).
L’esecuzione speculativa porta però a casi in cui alcune istruzioni potrebbero venire eseguite senza che siano richieste. Infatti per mantenere le pipe impegnate, vengono elaborate alcune istruzioni di cui si ipotizza il possibile uso (speculation). Se in seguito l’istruzione elaborata non risultasse affatto necessaria, il risultato verrà eliminato.
Ma l’esecuzione di istruzioni non necessarie comporta un consumo inutile di risorse, anche se a volte questo viene considerato un giusto compromesso per ottenere prestazioni più elevate.
Il branch predictor viene quindi utilizzato per scegliere il percorso più probabile che l’esecuzione del programma intraprenderà nella sequenza di istruzioni, molto prima che si sappiano se queste istruzioni siano necessarie o meno.
Comunque per dimostrare i benefici della speculazione (speculation) vediamo un altro esempio, questa volta contenente una istruzione condizionale if.
t = a+b u = t+c v = u+d if v: w = e+f x = w+g y = x+h
Ora abbiamo delle dipendenze: infatti u della seconda istruzione dipende dal calcolo di t nella prima. v della terza istruzione dipende dal calcolo di u nella seconda istruzione. La stessa cosa per le tre istruzioni dentro il blocco if : y dipende dal calcolo di x che dipende dal calcolo di w, ognuna per essere calcolata ha bisogno che la precedente istruzione venga calcolata.
Assumendo che il comando if richieda un ciclo macchina, il nostro esempio potrebbe richiedere o 4 cicli (nel caso in cui v fosse zero) o 7 cicli (nel caso in cui v non è zero).
Adesso se il branch predictor ipotizza che il blocco del ciclo if è molto probabile che debba essere eseguito. Per speculazione (speculation) la sequenza di istruzioni viene modificata in questo modo:
t = a+b u = t+c v = u+d w_ = e+f x_ = w_+g y_ = x_+h if v: w, x, y = w_, x_, y_
Ora dato che abbiamo un livello di parallelismo aggiuntivo possiamo accoppaire le istruzioni per mantenere due pipe occupate. Abbiamo così 5 cicli richiesti per eseguire tutte le istruzioni del codice.
t, w_ = a+b, e+f u, x_ = t+c, w_+g v, y_ = u+d, x_+h if v: w, x, y = w_, x_, y_
Nel raro caso (almeno per speculazione) v risultasse 0, avremo comunque perso un solo ciclo (5 cicli invece di 4) contro i 2 che guadagnamo nel caso più probabile (5 cicli invece di 7).
La cache
Nei tempi passati, la velocità di un processore veniva uguagliata dalla velocità di accesso alla memoria. Quindi un processore di 2MHz poteva eseguire un’istruzione ogni 2µs (microsecondi), e aveva un tempo per ogni ciclo di memoria di 0.25µs. Con il passare degli anni la velocità dei processori ha continuato ad aumentare, mentre quella della memoria no. Per esempio, un Cortex-A53 (Raspberry Pi 3) può eseguire un’istruzione ogni circa 0.5ns (nanoseconds), ma impiega ben 100ns per accedere alla memoria principale.
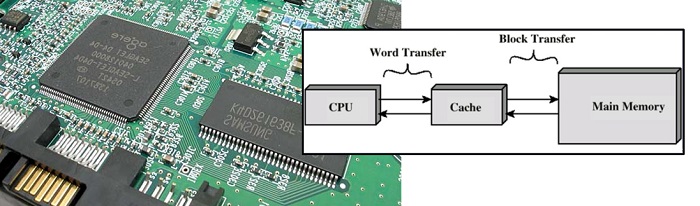
In un primo momento, questa situazione potrebbe sembrare disastrosa, cioè attendere ben 200 cicli a vuoto da parte del processore prima di accedere a nuovi valori in memoria.
Quindi eseguire due istruzioni come le seguenti
a = mem[0] b = mem[1]
richiederebbe ben 200 ns!
In pratica, comunque, si è scoperto che i programmi tendono ad accedere alla memoria in modo facilmente prevedibile, esibendo sia località temporale ( se accedo ad una locazione di memoria è molto probabile che dovrò accederci ancora), e località spaziale (se accedo ad una locazione è molto probabile che dovrò accedere a quella vicina).
Quindi il caching è quel meccanismo che sfrutta queste due regole per ridurre i costi medi di accesso alla memoria.
Una cache è una piccola unità di memoria su un chip, posta vicino al processore, che immagazzina copie del contenuto recentemente utilizzato (e contenuti di locazioni vicine), in modo che siano più velocemente disponibili a successivi accessi. Con il caching, l’esempio sopra verrà eseguito in poco più che 100ns.
a = mem[0] # 100ns delay, copies mem[0:15] into cache b = mem[1] # mem[1] is in the cache
Attacchi di tipo side channel
Come definito su Wikipedia, un side-channel attack è un qualsiasi attacco basato su informazioni ottenute dall’implementazione fisica di un criptosistema, piuttosto che con la forza bruta o la debolezza di un algoritmo. Per esempio, informazioni di timing, del consumo di energia o carenze elettromagnetiche possono fornire informazioni che possono essere sfruttate per rompere il sistema.
Spectre e Meltdown sono attacchi di tipo side channel che riescono a dedurre il contenuto di una locazione di memoria che non dovrebbe essere normalmente accessibile utilizzando il timing per controllare se un’altra locazione di memoria accessibile è presente sulla cache.

Il meccanismo di Meltdown
Ora diamo un’occhiata a come i processi di speculazione (speculation) e caching combinati insieme possono permettere un attacco di tipo Meltdown sul nostro processore. Considerando il seguente esempio, che è un programma utente che qualche volta legge da un indirizzo illegale del kernel, risultando in un fault (crash del sistema).
t = a+b u = t+c v = u+d if v: w = kern_mem[address] # if we get here, fault x = w&0x100 y = user_mem[x]
Ora, supponendo di poter far intendere al branch predictor che v sia probabilmente diverso da zero, il nostro processeore superscalare a due vie e out-of-order convertirà la sequenza di istruzioni nel seguente modo:
t, w_ = a+b, kern_mem[address] u, x_ = t+c, w_&0x100 v, y_ = u+d, user_mem[x_] if v: # fault w, x, y = w_, x_, y_ # we never get here
Da questo, tutto sembra sicuro dato che:
- se v è zero, il risultato della lettura illegale non viene inviato a w
- se v è diverso da zero, il fault (della lettura illegale) avviene prima che la lettura sia inviata a w
Comunque, supponiamo di fare il flush della nostra cache prima di eseguire il codice, ed arrangiare a,b,c e d in modo che vi sia uguale a zero. Ora la lettura speculativa del terzo ciclo
v, y_ = u+d, user_mem[x_]
accederà all’indirizzo 0x000 o all’indirizzo 0x100 a seconda degli 8 bit del risultato della lettura illegale, caricando quell’indirizzo ed il suo vicino nella cache. Dato che v è uguale a zero, i risultati delle istruzioni speculative verranno scartati, e l’esecuzione continuerà. Se abbiamo un accesso successivo ad uno di questi indirizzi, possiamo determinare quale indirizzo è presente nella cache. Congratulazioni: hai appena letto un single bit da uno spazio di indirizzi del kernel.
Meltdown in realtà sfrutta un meccanismo più complesso di questo, ma il principio alla base è lo stesso.
Spectre utilizza un approccio simile per ingannare i controlli (check bounds) del software.
Conclusione
Ma i processori utilizzati in Raspberry PI come
- ARM1176 (Raspberry Pi 1),
- Cortex-A7 (Raspberry Pi 2)
- Cortex-A53 Raspberry Pi 3)
non fanno uso della speculazione (speculation) e proprio per questo motivo sono immuni agli attacchi di questo genere.[:en]