Lately there has been a lot of talk about these Large Language Models, even though many times we don’t even realize it. Tools like Chat GPT-3, and other AI applications are based on these models and are increasingly entering our lives. It is therefore important to delve deeper into this type of concept and understand what they consist of, how they are structured and how they work. In this article we will see, we try to give an overview on this topic. For those who would like to learn more, we suggest visiting other more detailed articles on the subject.
What are Large Language Models
Large Language Models (LLM) are artificial intelligence models that have demonstrated remarkable capabilities in the field of natural language. They mainly rely on complex architectures that allow them to capture linguistic relationships in texts effectively. These models are known for their enormous size (hence the term “Large“), with millions or billions of parameters, which allows them to store vast linguistic knowledge and adapt to a variety of tasks.
In summary, these AI models based on transformer neural networks, trained on large amounts of text to learn the structure and meaning of natural language. They use the self-attention mechanism to capture relationships between words and are capable of generating and understanding text contextually.
Transformer neural networks
A Transformer neural network is a particular artificial neural network architecture that was introduced in 2017 by Vaswani et al. con l’articolo “Attention Is All You Need“. It has become one of the most influential and widely used architectures in the field of natural language and machine learning.
The Transformer architecture is characterized by two key aspects:
- Self-attention mechanism: The defining feature of Transformers is the self-attention mechanism, which allows the model to assign different weights to words in a sequence depending on their context. This mechanism allows you to capture relationships between words efficiently and manage long-range dependencies within the text. In short, the network can “pay attention” to specific parts of the text in an adaptive way.
- Non-recurrence structures: Unlike recurrent neural networks (RNNs), which treat sequences of data sequentially, Transformer networks work in a highly parallel manner. This means they can process input more efficiently and scalably, which has made it possible to train models with many parameters..

block contains multiple sub-modules, including:
- Multi-Head Self-Attention: This module calculates self-attention on a sequence of inputs, allowing the model to assign different weights to each word based on context.
- Feed Forward: These layers of Feed Forward neural networks are inserted to process the self-attention data and produce intermediate representations.
- Add & Norm: These layers are used to stabilize the learning process.
- Residual Connections: Each block contains residual connections to facilitate gradient propagation during training.
Transformer networks can be used in several configurations, including encoder-decoder for machine translation, single encoder for entity recognition, or decoder-only for text generation. This architecture is highly adaptable and flexible, and has been the basis of many of the successful Large Language Models (LLMs) that have emerged in recent years, such as BERT, GPT-3, and others.
How Large Language Models work
When you ask a Large Language Model (LLM) a question via chat, the model goes through a process of understanding the question and will then generate an answer to provide a coherent and meaningful conversation.
The process begins with the model analyzing the demand. This involves breaking the question into smaller units called “tokens” (tokenizing the entered text), such as words or subsets of words, to make it more manageable. Next, the model tries to understand the meaning of the question, identifying key words, dependencies between words and the context in which the question is asked. This understanding phase is crucial to understanding what the user is trying to achieve.
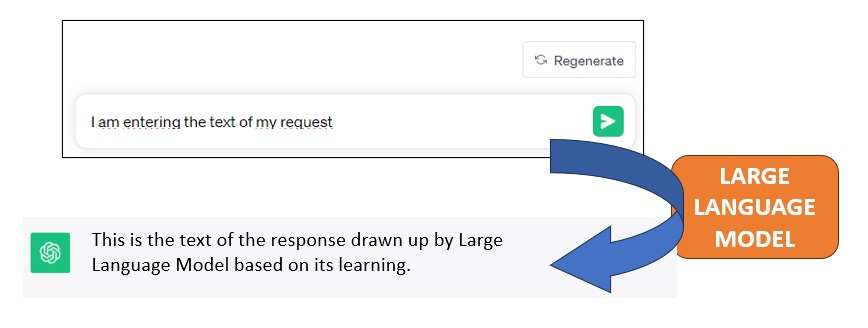
Once the model understands the question, it moves on to generating the answer. Using information acquired during training on large amounts of text, the model generates an answer that is consistent and informative in relation to the question asked. This answer may vary based on the complexity of the question, the specificity of the context, and the knowledge accumulated by the model.
In some situations, the model may generate more than one possible answer and then select the one it deems most appropriate based on criteria such as consistency, relevance, and accuracy. This process allows the model to adapt its responses to the user’s specific needs.
The development phases of a Large Language Model
Finally, the model returns the final response to the user via the chat or interface in use. However, it is important to note that the quality of your responses may vary depending on your understanding of the model and the information available to you. Additionally, LLMs do not have an inherent understanding of the world and base their responses on training data, meaning they may not always be up to date or reflect the latest developments.
Developing a Large Language Model (LLM) is a complex process and requires a series of key steps. Here is an overview of the typical steps involved in developing an LLM:
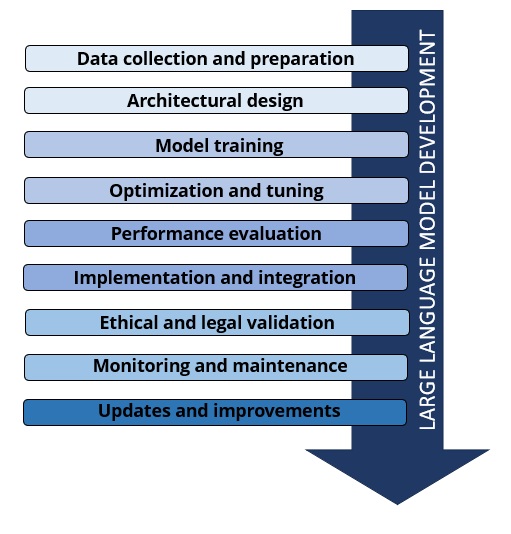
- Data collection and preparation: The first step is to collect a large amount of natural language texts from various sources, such as books, articles, websites, social media and more. This data will serve as a training corpus for the model. It is important to clean and prepare the data, removing unwanted or noisy data and standardizing the format. The collected data must be “tokenized” and broken down into smaller units, such as words or subsets of words (tokens). Additionally, it is common to apply normalization techniques, remove punctuation, and manage case.
- Architecture Design: Designing the architecture of the model is a crucial step. You need to decide on the size of the model (i.e., the number of parameters), the depth of the network, and other architectural details. Transformer architecture is often used as a basis.
- Model training: This is one of the most resource-intensive steps. The model is trained on the prepared data corpus. During training, the model tries to predict next words or sentences in texts. Training can require a lot of time and computing power, and is often performed on clusters of high-powered servers.
- Optimization and tuning: Once trained, the model can undergo several optimization phases to improve performance. This can include tuning hyperparameters, fine-tuning on specific tasks, and optimizing the architecture itself.
- Performance evaluation: It is important to evaluate the model’s performance on a number of metrics relevant to the specific task. This helps determine how well the model performs the task and identify any areas for improvement.
- Deployment and Integration: Once the model has achieved the desired performance, it can be deployed and integrated into an application or system. This may require optimization for efficiency and scalability.
- Ethical and legal validation: It is important to consider the ethical and legal implications of using the model, such as data privacy, generated content, discrimination, and other ethical and regulatory aspects.
- Monitoring and maintenance: After implementation, the model requires continuous monitoring to ensure that its performance is stable and that unexpected problems do not emerge.
- Updates and improvements: Language models can benefit from subsequent updates, both to adapt to new data and to improve performance. It is important to continue to develop and improve the model over time.
These steps represent a general overview of the process of developing a Large Language Model. Each phase requires significant expertise and resources, and the success of the model will depend on the quality of the data, architecture, training and validation.
Some of the best-known Large Language Models
Here are some examples of the most well-known and widely used LLMs. There are many other variants and specialized models that are constantly being developed to address specific natural language-related tasks. Each model has its own features and benefits, and the choice of model often depends on the specific needs of the application.
- GPT-3 (Generative Pre-trained Transformer 3): GPT-3 is one of the best-known and most advanced LLMs. Developed by OpenAI, it is made up of 175 billion parameters and is known for its ability to generate consistent, quality text across a wide range of language-related tasks.
- BERT (Bidirectional Encoder Representations from Transformers): BERT, developed by Google, is known for its ability to understand context and bidirectional text processing. It has proven effective in tasks such as entity recognition, sentence completion, and sentiment analysis.
- T5 (Text-to-Text Transfer Transformer): T5 is another transformer model developed by Google that takes a “text-to-text” approach, treating both input and output data as sequences of text. This model is highly flexible and can be used for a wide range of tasks, such as machine translation and text generation.
- RoBERTa (A Robustly Optimized BERT Pretraining Approach): RoBERTa is a variant of BERT developed by Facebook AI Research (FAIR) that focuses on optimizing pre-scaling training. He demonstrated superior performance on a range of language tasks.
- XLNet: XLNet is another transformer-based model developed by Google Brain and Carnegie Mellon University. It is based on a pre-training variant that takes into account all possible permutations of words in a sentence. This approach improves understanding of context and generation of coherent text.
- Turing-NLG: Turing-NLG is an LLM developed by Microsoft and is known for its exceptional performance in natural language text generation. It has been used in chatbot and content generation applications.
- DistilBERT: DistilBERT is a lighter and faster version of BERT developed by Hugging Face. Although it has fewer parameters than BERT, it maintains decent performance in a variety of language tasks.
Some applications of Large Language Models
Large Language Models (LLMs) have found applications in a wide range of natural language-related fields and tasks. Below are some of the most important and relevant applications:
- Automatic translation
- Text generation
- Chatbot and virtual customer assistant
- Sentiment analysis
- Grammatical correction
- Research and analysis of texts (insights, summaries, etc.)
- Automatic source code generation
- Education (virtual tutors, machine learning tools and personalized learning materials).
- Creation of multimedia content (image and video descriptions, subtitles, audio scripts and much more).
- Creating automated customer support responses
These are just a few of the many applications of Large Language Models, and the use of these technologies continues to expand across a wide range of industries.