In this third part of the Thread in Python series, we will look at some aspects of multithreading. In fact, in fact, threads can be very different from each other and often recursion methods to create and manage them, such as for loops, can no longer be used. There are therefore tools that allow you to manage different threads like ThreadPoolExecutor. However, thread management remains a complex operation that, if not well managed, can lead to problems such as the Race Condition. In this article we will look at these two aspects in detail.

ThreadPoolExecutor
When threads begin to be many, an efficient way to manage them is the ThreadPoolExecutor. This interface belongs to the concurrent.futures module and is created as a context manager, using the with statement.
The previous program, including joins for all threads, can be transformed into the following.
import concurrent.futures
import time
def thread1():
print("Thread 1 started")
time.sleep(10)
print("Thread 1 ended")
def thread2():
print("Thread 2 started")
time.sleep(4)
print("Thread 2 ended")
print("Main start")
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(thread1)
executor.submit(thread2)
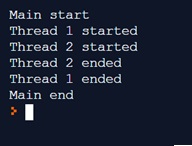
print("Main end") The result of the execution will be the same, only that the management of the different threads is performed within the ThreadPoolExecutor context manager, without having to define, either individually or within iterations, the call to the start() and join() functions.
Race Conditions
Another concept related to threading is that of race conditions.
These particular conditions occur when two or more threads access a set of shared data or resources. If not well managed, a thread’s access and modification to these resources can lead to inconsistent results.
For simplicity of example, we will use shared variables as resources. In real cases, race conditions occur when multiple threads want to access the same data on a database.
To simulate in a certain way this condition, we will create a variable containing a value (shared resource) within an object of a FakeDatabase class, which simulates a database (very far from reality, but just a little imagination … 😉 ).
We will insert a starting value within this variable equal to 0. Then we will create three different threads that will have the task of increasing, each of them, this value of 1, accessing this hypothetical database. At the end of this operation (program) we should expect a value of 3 as a result.
Enter the following code
import concurrent.futures
import time
class FakeDatabase:
def __init__(self):
self.value = 0
def update(self, name):
print("Thread ", name , "is reading the DB value")
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
print("Thread ", name ,"has modified the DB value")
database = FakeDatabase()
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
for index in range(3):
executor.submit(database.update, index+1)
print("DB Value is ", database.value) By executing the code, we will get:
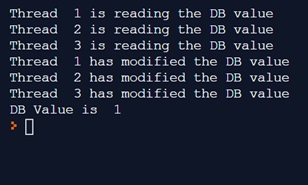
As we can see the final value on the DB is 1. When in reality it should be 3, since the contribution of each thread is 1. But unfortunately each of them has acquired the initial value.
We therefore had a condition of race condition, in which the three threads worked in a competitive manner, with each having its own local version of the value read by the database (local_copy) acquired in a competitive (indeterminate) manner.
In our example, all three threads access the same initial value, without waiting for others to make their contribution. They will perform their operations independently locally (local_copy incremented by one). And then they will overwrite the value on the database.
As well as structured that the threads are 3 or one, it is practically the same thing.
In reality the cases are much more complex, and the evidence of race condition can assume the most varied forms, with consequences of anomalous behaviors and unexpected results.
Conclusions
In this third part we have seen the first cases of Multi threading with the introduction of the Race Condition problem and the ThreadPoolExecutor tool that allows to better manage multiple threads simultaneously. In the following part, we will explore Multi threading in other ways, such as the use of Lock in threads and the deadlock issue.