Introduction
This article is taken from a beautiful post by Eben Upton. Recently there has been a lot of discussion about some security vulnerabilities found in many processors, called Spectre and Meltdown. There are many processors that have been found to be vulnerable to these attacks, including many processors as Intel, AMD and even some ARM cores.
Upton wanted to write a wonderful article explaining how all Raspberry Pi models are immune to this vulnerability. I tried to summarize in a big way what the article says, otherwise you can easily read the original one.

Spectre e Meltdown
This new kind of vulnerability exploits some defects, or better, ‘holes’ in the architecture of the processor, unavoidable when the architectures gradually become more and more complex. In fact, in an attempt to make the processors more efficient, and if you want to overcome the limits of an architecture, you will have to create increasingly complex mechanisms. These mechanisms can show over time the logical “deficiencies” in the controls. This is because in the logical passage to the real one it is impossible to take into account all the possible occurrences.
In this case, special innovations in mechanisms of processors, such as caching and the speculative execution, have led to huge increases in their performance, but have also introduced vulnerabilities. These two types of vulnerabilities have been named Spectre e Meltdown.

Spectre was discovered by researchers by a series of researchers and was made public, along with Meltdown, January 3, 2018. Spectre is able to force running programs to access memory locations that should be inaccessible (in theory ) to the program. Specter does this by bypassing the internal controls of the processor very cleverly.
Meltdown is always based on a vulnerability of the processors but uses the operating systems (all included) by exploiting the mechanism of critical execution of the CPU between the various instructions that access the memory. Meltdown also lets you read data from an arbitrary location in the operating system kernel address space.
Are Raspberry Pi cards vulnerable to Specter and Meltdown?
The answer is as beautiful as it is simple. Fortunately, no Raspberry Pi board is susceptible to these vulnerabilities, due to the particular ARM cores that they use.
But to better understand what Specter and Meltdown are and what mechanisms are used by them within the processor, it is necessary to give a series of examples of each mechanism involved in a very simple and summarized manner.
In this regard, we will base the whole example on an example that includes a sequence of 6 instructions: simple expressions with variables.
t = a+b u = c+d v = e+f w = v+g x = h+i y = j+k
If you want to deepen the topic on how a processor is designed, what are the various current architectures on which they are based and the mechanisms within them, there is no better book than Computer Architecture: A Quantitative Approach by Hennessy and Patterson (see below).
| Computer Architecture: A Quantitative Approach |
Now you will see some descriptions on the classes of processors useful for understanding their internal mechanism.
The scalar processors
The simplest type of modern processor executes one instruction per cycle. This is called a scalar processor. The example of the sequence of instructions that we wrote above will require 6 cycles to be executed by a scalar processor, as the 6 instructions are shown.
Examples of these scalar processors are found in the 486 of Intel and in the ARM1176 core used in both Raspberry Pi 1 and Raspberry Pi Zero.
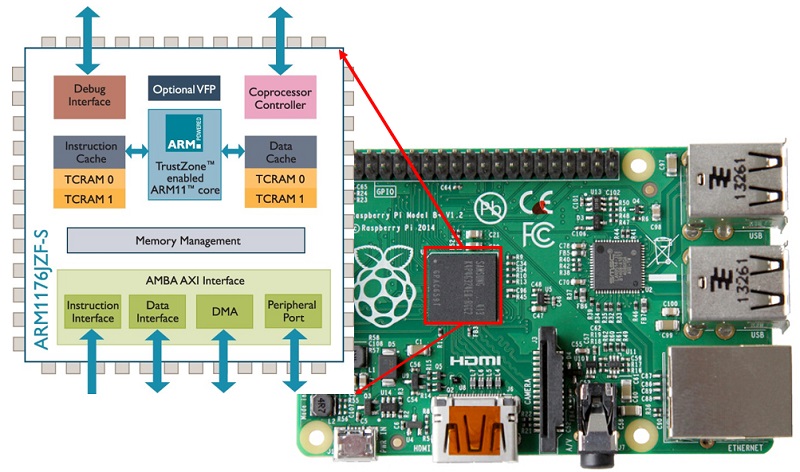
The superscalar processor
The most obvious way to make a scalar processor faster is to make it faster, increasing its clock speed. However, by operating in this way, the processor soon reaches the limits imposed by the logic gate speeds inside the processor. So the designers had to look for other solutions.
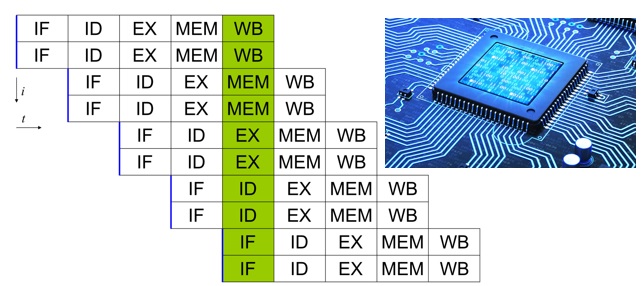
A superscalar processor examines the flow of incoming instructions and tries to execute several of them at the same time, using different pipelines (pipes). But these pipelines are subject to any dependencies between the various instructions. Dependencies are important factors to consider.
In fact, a two-way superscalar processor could theoretically couple the six instructions of the example in a sequence of three pairs of instructions.
t, u = a+b, c+d v, w = e+f, v+g x, y = h+i, j+k
But this would not benefit at all. In fact, if you take a look at the second pair of instructions, you will notice that you will first need to calculate v to then calculate w. So there is a dependency between the two instructions and therefore the second pair of instructions can not be executed at the same time.
A two-way superscalar processor can then carry out the above instructions in 4 cycles. In the second cycle and in the fourth cycle, one of the two pipes will remain empty
t, u = a+b, c+d v = e+f # second pipe does nothing here w, x = v+g, h+i y = j+k
Examples of superscalar processors include Intel Pentium, and ARM Cortex-A7 (Raspberry Pi 2), ARM Cortex-A53 (Raspberry Pi 3).


The out-of-order superscalar processors
Returning to the example, as you did with a dependency between two variables, such as v and w, you could likewise take advantage of another set of dependent instructions. One of these dependencies could potentially be used to fill the second pipe left empty.
An out-of-order processor is able to change the order of incoming instructions in order to always fill all the pipes. In our example, the processor reverses the definitions of w and x in the sequence:
t = a+b u = c+d v = e+f x = h+i w = v+g y = j+k
Now you have the possibility to execute all the instructions in just 3 cycles.
t, u = a+b, c+d v, x = e+f, h+i w, y = v+g, j+k
Examples of out-of-order processors include the Intel Pentium 2 and later and the AMD x86 processors, and many ARM cores with Cortex-A9, -A15, -A17, and -A57.
Branch prediction
The example you’ve seen so far is a piece of code with a linear sequence of instructions. In reality the programs are not in this way, in fact there are possible branches in the sequence of instructions. For example, whenever the “if” statement is present in a code, there is a branch of the instruction sequence. These ramifications can be unconditioned (they are always executed) or conditioned (they are executed according to some values). Furthermore, these branches can be direct (explicitly specifying a target address) or indirect (the target address is taken from a dynamic memory register or location).

While a processor retrieves the instructions to be executed, it may encounter a conditional branch that depends on a value that must still be calculated. To avoid a deadlock, the processor must guess what the next instruction to be recovered will be: the next following the order in memory (corresponding to a branching not undertaken) or to that of the target branch (corresponding to the branching undertaken). A branch predictor helps the processor to make intelligent assumptions about which branching has been taken or not. This operation is performed by collecting statistics on how often these ramifications were taken in the past.
The modern predictors branches are extremely sophisticated and can generate very accurate predictions. The high performance of Raspberry Pi 3 compared to Raspberry Pi 2 (much more than 33% expected) is largely due to the difference of the predictors used between Cortex-A7 and Cortex-A53 processors.
However, an attacker could be able to have a studied sequence of ramifications carried out, leading to bad training of the branch predictor, then leading to bad predictions.
Speculative execution
Sequencing instructions sequentially is a powerful way to recover parallelism at the level of instructions, but as processors become larger (ie able to execute three or four instructions), it becomes increasingly difficult to keep all pipes occupied. The modern processors have therefore increased their ability to speculate.
However, speculative execution leads to cases in which some instructions could be executed without being required. In fact, to keep the pipes engaged, some instructions are elaborated, which are hypothesized the possible use (speculation). If the processed instruction is not necessary at all, the result will be deleted.
But the execution of unnecessary instructions leads to a useless consumption of resources, even if sometimes this is considered a fair compromise to obtain higher performances.
The branch predictor is then used to choose the most likely path that program execution will take in the sequence of instructions, long before we know whether these instructions are necessary or not.
However to demonstrate the benefits of speculation, you will now see another example, this time containing a conditional if statement.
t = a+b u = t+c v = u+d if v: w = e+f x = w+g y = x+h
Now you can see dependencies: in fact, u of the second statement depends on the calculation of t in the first. v of the third instruction depends on the calculation of u in the second instruction. The same thing for the three instructions inside the if block: y depends on the calculation of x that depends on the calculation of w, each to be calculated needs the previous instruction to be computed.
Assuming that the if command requires a machine cycle, this example could require either 4 cycles (in the case where v was zero) or 7 cycles (in the case where v is not zero).
Now if the branch predictor assumes that the block of the if loop is very likely to be executed. For speculation, the sequence of instructions is changed like this:
t = a+b u = t+c v = u+d w_ = e+f x_ = w_+g y_ = x_+h if v: w, x, y = w_, x_, y_
Now since there is an additional level of parallelism, you can support the instructions to keep two pipes busy. You have 5 cycles required to perform all the code instructions.
t, w_ = a+b, e+f u, x_ = t+c, w_+g v, y_ = u+d, x_+h if v: w, x, y = w_, x_, y_
In the rare case (at least for speculation) v turns out to be 0, you will still have lost only one cycle (5 cycles instead of 4) against the 2 that we earn in the most probable case (5 cycles instead of 7).
The cache
In times past, the speed of a processor was equaled by the speed of access to memory. So a 2MHz processor could execute an instruction every 2μs (microseconds), and had a time for every memory cycle of 0.25μs. Over the years the speed of the processors has continued to increase, while that of the memory no. For example, a Cortex-A53 (Raspberry Pi 3) can execute an instruction every about 0.5ns (nanoseconds), but it takes as many as 100ns to access the main memory.
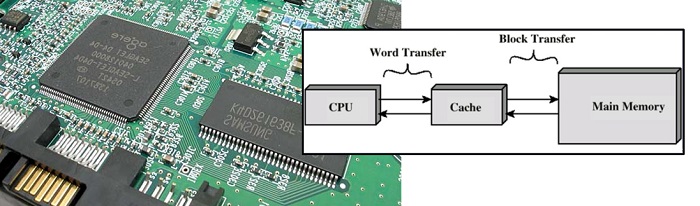
At first, this situation may seem disastrous, that is, to wait a good 200 empty cycles by the processor before accessing new values in memory.
So to perform two instructions like the following
a = mem[0] b = mem[1]
it would require as many as 200 ns!
In practice, however, it has been discovered that programs tend to access memory in an easily predictable way, exhibiting both temporal location (if I access a memory location it is very likely that I will have to access it again), and spatial location (if I access a leasing is very likely that I will have to access the neighbor).
So caching is the mechanism that exploits these two rules to reduce average memory access costs.
A cache is a small unit of memory on a chip, placed near the processor, which stores copies of the recently used content (and contents of nearby locations), so that they are more readily available for subsequent accesses. With caching, the above example will run in little more than 100ns.
a = mem[0] # 100ns delay, copies mem[0:15] into cache b = mem[1] # mem[1] is in the cache
Side channel attacks
As defined on Wikipedia, a side-channel attack is any attack based on information obtained from the physical implementation of a cryptosystem, rather than with the brute force or weakness of an algorithm. For example, timing information, energy consumption or electromagnetic deficiencies can provide information that can be exploited to break the system.
Spectre and Meltdown are side channel attacks that can deduce the contents of a memory location that should not normally be accessible using timing to check if another accessible memory location is present on the cache.
The Meltdown mechanism
Now take a look at how the speculation and caching processes combined together can allow a Meltdown attack on your processor. Considering the following example, which is a user program that sometimes reads from an illegal kernel address, resulting in a fault (system crash).
t = a+b u = t+c v = u+d if v: w = kern_mem[address] # if we get here, fault x = w&0x100 y = user_mem[x]
Now, supposing we can make the branch predictor v think that it is probably non-zero, the two-way and out-of-order superscalar processor will convert the instruction sequence as follows:
t, w_ = a+b, kern_mem[address] u, x_ = t+c, w_&0x100 v, y_ = u+d, user_mem[x_] if v: # fault w, x, y = w_, x_, y_ # we never get here
From this, everything seems safe given that:
- if v is zero, the result of illegal reading is not sent to w
- if v is non-zero, the fault (of illegal reading) occurs before the reading is sent to w
However, suppose you flush our cache before executing the code, and arrange a, b, c, and d so that it is zero. Now the speculative reading of the third cycle
v, y_ = u+d, user_mem[x_]
will access the address 0x000 or the address 0x100 according to the 8 bits of the result of the illegal reading, loading that address and its neighbor in the cache. Since v is equal to zero, the results of the speculative instructions will be discarded, and execution will continue. If you have subsequent access to one of these addresses, you can determine which address is in the cache. Congratulations: you just read a single bit from a kernel address space.
Meltdown actually exploits a more complex mechanism than this, but the underlying principle is the same.
Spectre uses a similar approach to fool the checks (checks bounds) of the software.
Conclusions
But the processors used in Raspberry PI like
- ARM1176 (Raspberry Pi 1),
- Cortex-A7 (Raspberry Pi 2)
- Cortex-A53 Raspberry Pi 3)
they do not make use of speculation and for this reason they are immune to such attacks.[:]