In this article we will continue the Multithreading speech, introducing another very important tool: the Lock. Thanks to these, synchronization between the various threads can be managed more efficiently. We will also talk about another common problem in the thread world: deadlocks.

- Thread in Python – Threading (part 1)
- Thread in Python – Join (part 2)
- Thread in Python – Multithreading (part 3)
Lock and the Basic Synchronization
We saw in the previous example a very simple case of race condition. The threading module provides us with some tools to avoid, or solve, the race condition events. One of these is the Lock.
A Lock is an object that acts as a permit. The lock will be assigned to only one thread at a time. The other threads will wait for the lock owner to complete its task and return it. Thanks to the Lock mechanism it will be possible to control the competition between the various threads, ensuring that each one of them performs its activities without the unwanted interference of the other threads.
In our example, each thread must receive the lock, perform read-calculate-write operations and then return the lock to the others. In this way we will have control over the correct sequence of events between the various threads eliminating the race condition.
There are a number of functions for using locks within a program. The acquire() and release() functions, for example, have the task of having the lock acquired and released. If the lock is already in possession of another thread, the calling thread will remain on hold until the lock is released.
Attention, so far it seems all positive. There might be the case that a thread that has received a lock, for some reason, never returns it. In this case the program would remain completely blocked.
To avoid these cases, the locks of the threading module have been designed to work also as a context manager, within a statement with. With this system, the lock will still be released automatically when the block with ends. In this way we will see that it will not be necessary to call the acquire() and release() functions, but everything will be managed by the context manager.
We see all these concepts in the following example.
We import the threading module into the previous code
import threading
Then in the FakeDatabase class, we add a Lock.
class FakeDatabase: def __init__(self): self.value = 0 self._lock = threading.Lock()
Now instead of using acquire() and release(), we use the construct with creating a context manager that will efficiently handle the lock.
Therefore, in the function that implements the thread, we write the context manager and inside it we insert all the code that would generate the race condition.
with self._lock:
print("Thread ", name , "has received the lock")
…
print("Thread ", name, " is releasing the lock") As we can see inside, the acquire() and release() functions are not used for the acquisition and release of the lock, but it is managed implicitly and efficiently by the context manager structured with.
At the end of all changes and additions the final code is as follows:
import concurrent.futures
import time
import threading
class FakeDatabase:
def __init__(self):
self.value = 0
self._lock = threading.Lock()
def update(self, name):
print("Thread ", name , "is reading the DB value")
with self._lock:
print("Thread ", name , "has received the lock")
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
print("Thread ", name ,"has modified the DB value")
print("Thread ", name, " is releasing the lock")
database = FakeDatabase()
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
for index in range(3):
executor.submit(database.update, index+1)
print("DB Value is ", database.value) By executing it, we will get the following result
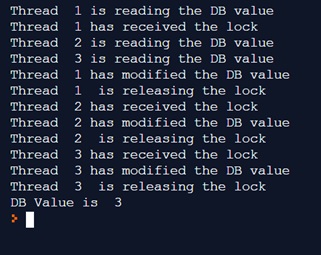
From the output you can see that the threads are now working correctly. Thread 1 is the first to receive the lock, then only when it has changed the value in the DB, the lock will be released and passed to thread 2, and so on, sequentially (mutual exclusion).
In the end the value on the DB is correctly 3.
Deadlocks
The use of locks is an optimal solution to avoid race condition problems, but sometimes, especially if used outside of the construct with, they can create some problems.
We have already said that in this case it will be necessary to manage the locks with the acquire() and release() methods, and once the lock has been acquired by a thread, all the other threads will have to wait for its release before proceeding further. This, if not well managed, can lead to deadlocks. That is, if for some reason the thread with the lock will never release it, the program will remain locked.
import threading l = threading.Lock() ... l.acquire() ... l.release()
Deadlocks normally occur in one of the following cases:
- A bad implementation of threads where a Lock is not released properly
- A problem in the design scheme of a program that does not correctly foresee all the possible calls from the blocked threads waiting for the lock, and that are necessary for the completion of the thread with the lock
The first situation can be quite common, but using a Lock as a context manager greatly reduces the chance of ending up in a deadlock. It is therefore recommended, where possible, to always use context managers.
As for the second case, that is the problems with the design, in the threading module there is an object called RLock, designed to solve some of these situations, not all of them.
Conclusions
In this fourth part we have seen other aspects of Multithreading such as the use of Lock and the Deadlock problem. In the following part we will introduce the Producer-Consumer model, which uses threads and is very common in the world of computer development.