La Matrice di Confusione
La matrice di confusione è uno strumento di valutazione ampiamente utilizzato nel machine learning per misurare le prestazioni di un modello di classificazione. Fornisce una panoramica dettagliata delle previsioni fatte dal modello rispetto alle classi reali dei dati. La matrice di confusione è particolarmente utile quando si lavora con problemi di classificazione in cui le classi possono essere più di due.
La matrice di confusione è organizzata in una tabella, in cui ogni riga rappresenta la classe reale e ogni colonna rappresenta la classe prevista dal modello. La diagonale principale della matrice rappresenta le previsioni corrette (veri positivi e veri negativi), mentre le celle fuori dalla diagonale rappresentano gli errori di classificazione (falsi positivi e falsi negativi).
Ecco come funziona la matrice di confusione:
- Veri Positivi (TP): Numero di casi in cui il modello ha previsto correttamente una classe positiva.
- Veri Negativi (TN): Numero di casi in cui il modello ha previsto correttamente una classe negativa.
- Falsi Positivi (FP): Numero di casi in cui il modello ha erroneamente previsto una classe positiva quando in realtà era negativa (falso allarme).
- Falsi Negativi (FN): Numero di casi in cui il modello ha erroneamente previsto una classe negativa quando in realtà era positiva (mancato rilevamento).
La matrice di confusione può aiutarti a comprendere quale tipo di errori il tuo modello sta commettendo e quale classe sta avendo prestazioni migliori o peggiori. A partire da questi valori, puoi calcolare diverse metriche di valutazione come l’accuratezza, la precisione, il richiamo e il punteggio F1.
La matrice di Confusione come strumento di analisi
La matrice di confusione è uno strumento importante per valutare le prestazioni di un modello di classificazione in dettaglio. Oltre a calcolare i valori di base come veri positivi, veri negativi, falsi positivi e falsi negativi, puoi utilizzare questi valori per calcolare diverse metriche di valutazione che forniscono una visione più completa delle prestazioni del modello. Ecco alcune delle metriche più comuni calcolate dalla matrice di confusione:
1. Accuratezza (Accuracy): L’accuratezza misura la proporzione di previsioni corrette rispetto al numero totale di previsioni. È la metrica più semplice ma può essere fuorviante quando le classi sono sbilanciate.
2. Precisione (Precision): La precisione rappresenta la proporzione di veri positivi rispetto al totale delle previsioni positive effettuate dal modello. Misura quanto il modello è preciso quando fa previsioni positive.
3. Richiamo (Recall o Sensibilità): Il richiamo rappresenta la proporzione di veri positivi rispetto al totale delle istanze positive effettive. Misura la capacità del modello di identificare tutte le istanze positive.
4. Punteggio F1 (F1 Score): Il punteggio F1 è la media armonica tra precisione e richiamo. È utile quando si desidera trovare un equilibrio tra precisione e richiamo.
5. Specificità (Specificity): La specificità rappresenta la proporzione di veri negativi rispetto al totale delle istanze negative effettive. Misura quanto il modello è bravo a identificare le istanze negative.
6. ROC Curve (Receiver Operating Characteristic Curve): La curva ROC è un grafico che mostra la relazione tra il tasso di veri positivi e il tasso di falsi positivi al variare della soglia di classificazione. A mano a mano che la soglia varia, i punti ROC vengono disegnati e collegati, e l’area sotto la curva ROC (AUC) può essere utilizzata come misura dell’efficacia del modello.
Queste metriche possono fornire un’analisi più approfondita delle prestazioni del modello rispetto a una semplice percentuale di accuratezza. È importante selezionare le metriche che sono più rilevanti per il tuo problema e per l’equilibrio tra precisione e richiamo desiderato.
Ricorda che queste metriche sono strumenti utili per valutare i modelli, ma dovresti sempre considerare il contesto del problema e la natura delle tue classi prima di trarre conclusioni sulla qualità del modello.

Se vuoi approfondire l’argomento e scoprire di più sul mondo della Data Science con Python, ti consiglio di leggere il mio libro:
Fabio Nelli
Un esempio pratico
Ecco un esempio di come utilizzare la matrice di confusione in Python:
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
# Carica il dataset Iris
iris = load_iris()
X = iris.data
y = iris.target
# Dividi il dataset in set di addestramento e di test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Crea e addestra un modello di classificazione (Random Forest)
model = RandomForestClassifier()
model.fit(X_train, y_train)In questo esempio, stiamo utilizzando come modello il RandomForestClassifier per effettuare una classificazione su un dataset di esempio come quello dei fiori IRIS inclusi nella stessa libreria sklearn per effettuare delle prove, come nel nostro caso. Una volta realizzato il modello ed effettuato l’apprendimento con il metodo fit(), possiamo testarlo.
y_pred = model.predict(X_test)
y_pred
array([1, 0, 2, 1, 1, 0, 1, 2, 1, 1, 2, 0, 0, 0, 0, 1, 2, 1, 1, 2, 0, 2,
0, 2, 2, 2, 2, 2, 0, 0])Otteniamo un array con le classi di appartenenza previste di fiori IRIS (0,1 e 2). Adesso possiamo applicare la matrice di confusione confrontando i risultati previsti (y_pred) con quelli reali dell’array y_test. Per quanto riguarda la matrice di confusione, non abbiamo bisogno di implementare nulla di nuovo, ma abbiamo il metodo già presente nella libreria sklearn sotto il modulo metrics. Calcoliamo quindi la matrice di confusione con il codice seguente:
cm = confusion_matrix(y_pred, y_test)
cm
array([[10, 0, 0],
[ 0, 9, 0],
[ 0, 0, 11]], dtype=int64)Visualizzazione della Matrice di Confusione
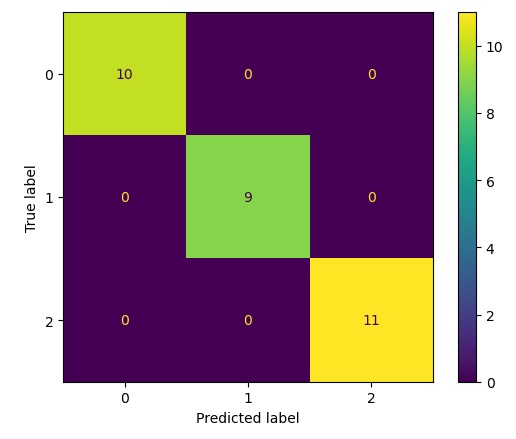
Ora che sappiamo come ottenere i valori della matrice di confusione rispetto ad un qualsiasi modello utilizzato, passiamo a vedere come sia possibile visualizzarli in una maniera grafica e più appropriata. Un modo per visualizzare la matrice di confusione ci viene fornito dallo stesso modulo sklearn.metrics, si tratta del della classe ConfusionMetrixDisplay.
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=clf.classes_)
disp.plot()
plt.show()Eseguendo si ottiene il seguente risultato.
Se non si vuole utilizzare l’oggetto ConfusionMetrixDisplay, la libreria matplotlib ci fornisce tutti gli strumenti necessari per lavorare graficamente e fornire una grafica alternativa di una matrice di confusione. Per esempio è possibile visualizzarla come HeatMap nel seguente modo:
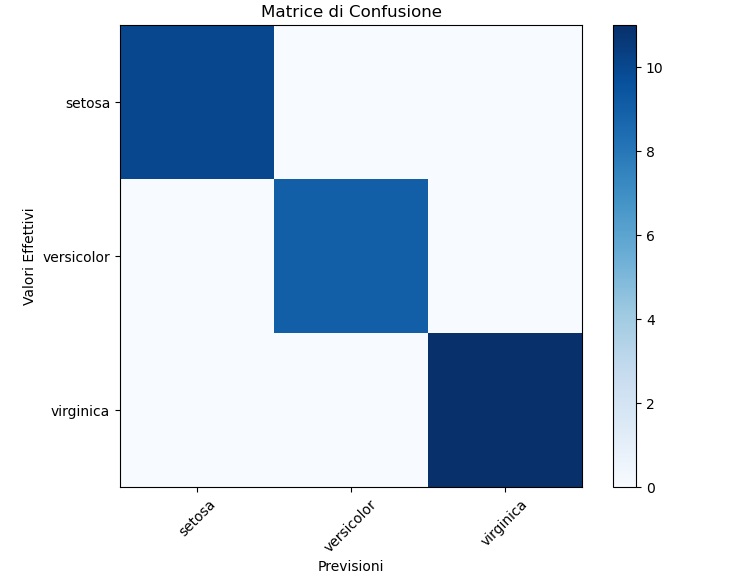
# Visualizza la matrice di confusione come una heatmap
plt.figure(figsize=(8, 6))
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title("Matrice di Confusione")
plt.colorbar()
plt.xticks(np.arange(len(iris.target_names)), iris.target_names, rotation=45)
plt.yticks(np.arange(len(iris.target_names)), iris.target_names)
plt.ylabel("Valori Effettivi")
plt.xlabel("Previsioni")
plt.show()
Eseguendo il codice si ottiene il seguente grafico: