Per cominciare a lavorare in modo efficace con R è importante conoscere almeno le tipologie di dato base ed almeno alcuni comandi fondamentali per poterci cominciare a lavorare. Una breve panoramica per cominciare a lavorare con questa splendida piattaforma.
Gli Array
Per definire un array in maniera molto semplice in R è sufficiente definire i valori degli elementi come parametri della funzione c() e poi assegnarli ad una variabile, con un nome qualsiasi, come per esempio a.
a <- c(1,3,5,7,9,11)per leggerne gli elementi al suo interno sarà sufficiente scrivere il nome dell’array, che in questo caso è a.
a
[1] 1 3 5 7 9 11Per accedere ad un singolo elemento dell’array si specifica il nome dell’array ed il suo indice tra parentesi quadre (posizione dell’elemento nell’array).
a[3]
[1] 5In questo modo è possibile anche modificare un elemento al suo interno, assegnandogli direttamente un nuovo valore.
> a[3] <- 33
> a
[1] 1 3 33 7 9 11Le sequenze
Un modo molto veloce per generare degli array è tramite l’uso di sequenze. Cioè un’istruzione o una serie di istruzioni che permettono in maniera semplice e veloce di generare un array anche con moltissimi elementi. Gli elementi però devono rispondere a determinate caratteristiche, cioè devono avere delle regole per poter definire le sequenze che li generano.
Per definire una sequenza in R si usa la funzione seq().
seq(2,40,4)
[1] 2 6 10 14 18 22 26 30 34 38dove il primo parametro è il valore di inizio, il secondo il valore finale e l’ultimo è la distanza tra porre tra gli elementi della sequenza.
Un altro modo per creare una sequenza di valori interi è quello di utilizzare i ‘:’ tra valore inziale e valore finale.
2:40
[1] 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
[26] 27 28 29 30 31 32 33 34 35 36 37 38 39 40Un altro modo per creare sequenze è con la funzione paste(). Questo modo è molto utile quando si vuole avere una sequenza alfanumerica con un prefisso o un suffisso in caratteri. Si inserisce quindi nel primo parametro un generatore di sequenza, e nel secondo il suffisso da aggiungere a ciascun elemento generato. La chiave del parametro sep definisce l’eventuale carattere separatore che si vuole aggiungere tra il suffisso e il valore della sequenza.
paste(1:6, "cm", sep="")
[1] "1cm" "2cm" "3cm" "4cm" "5cm" "6cm"Ma anche l’inverso, cioè nel primo argomento saranno specificati i caratteri alfanumerici che fungeranno da prefisso per la sequenza di valori che si genereranno nel secondo parametro. Se si vuole aggiungere un carattere separatore, basterà definirlo nel parametro sep.
paste("A", 1:5, sep =":")
[1] "A:1" "A:2" "A:3" "A:4" "A:5"Interessante è anche la possibilità di inserire entrambe i parametri come generatori di sequenza. I risultati possono essere interessanti.
> paste(1:3, 3:5, sep="")
[1] "13" "24" "35"
> paste(1:3, 3:8, sep="")
[1] "13" "24" "35" "16" "27" "38"Altro modo per creare una sequenza è con la funzione rep(). Questa funzione crea una sequenza di elementi tutti uguali. Il primo parametro è il valore da replicare, ed il secondo è il numero delle volte che deve essere replicato.
> rep(1, 5)
[1] 1 1 1 1 1Se invece vogliamo una sequenza di numeri casuali, si utilizza la funzione sample(). Nel primo argomento si passano il range di campioni da cui scegliere, il secondo parametro il numero di numeri casuali da generare, ed la chiave del terzo replace, se specificata TRUE come in questo caso, permette la ripetizione degli stessi valori nella sequenza, se FALSE la evita.
sample(1:10, 7, replace=T)
[1] 2 5 4 10 1 3 8Le possibilità di utilizzare questi comandi possono essere molte, come per esempio esiste la possibilità di scegliere tra un set di valori, passato come array, oppure scegliere tra una categoria di valori, come LETTERS che sono i caratteri dell’alfabeto.
sample(c(1,4,5,8,7,11,15),4, replace=F)
[1] 15 5 4 8
sample(LETTERS, 5, replace=T)
[1] "P" "Z" "Z" "X" "W"Ad ogni esecuzione di questi comandi otterremo dei valori diversi
sample(LETTERS, 7)
[1] "W" "D" "S" "X" "R" "U" "C"
sample(LETTERS, 7)
[1] "I" "T" "L" "G" "X" "H" "F"Se invece rendere la generazione di valori casuali in modo riproducibile è necessario specificare precedentemente ed ogni volta il comando set.seed().
set.seed(200)
> sample(LETTERS,5)
[1] "F" "R" "O" "H" "L"
> set.seed(200)
> sample(LETTERS,5)
[1] "F" "R" "O" "H" "L"Un esempio molto utile, può essere quello di simulare il lancio di un dado, per esempio, per 10 volte.
sample(1:6, 10, replace=T)
[1] 5 2 2 6 3 3 4 5 4 6Selezionare un sottoinsieme di elementi in un array
Adesso che sappiamo come creare un array, sia definendo elemento per elemento, che generandolo tramite sequenze. Sarà molto utile conoscere una serie di regole per poter accedere agli elementi al suo interno. Spesso è utile estrarre un insieme di elementi che sarà a sua volta un array (sub-array).
Selezione tramite condizioni
E possibile effettuare delle selezioni dei valori all’interno dell’array, imponendo delle condizioni. Se per esempio definiamo il seguente array
a <- c(1,3,5,7,9,11)Verrà restituito un sub array contenente solo gli elementi che rispondono alle condizioni imposte.
a[ a > 3 & a < 8]
[1] 5 7mentre se scriviamo in questo altro modo, otterremo un sub array contenente le posizioni degli elementi che rispondono alle condizioni imposte.
which( a > 3 & a < 8)
[1] 3 4Selezione tramite funzioni
Esistono anche determinate funzioni che effettuano particolari selezioni sugli array passati come parametro.
Definiamo un array di esempio attraverso una sequenza.
samples <- sample(1:100, 12, replace=T)
> samples
[1] 91 72 100 31 70 38 94 87 6 3 43 99E adesso vogliamo conoscere i primi e gli ultimi 6 elementi dell’array. In questo caso useremo le funzioni head() e tail().
head(samples)
[1] 91 72 100 31 70 38
> tail(samples)
[1] 94 87 6 3 43 99Statistiche sui valori di un array
Altre funzioni che ci fornisce R ci permette di valutare statisticamente i valori contenuti all’interno di un array.
Per esempio per conoscere il valore massimo e minimo, e il numero di elementi contenuti in un array.
> length(samples)
[1] 12
> max(samples)
[1] 100
> min(samples)
[1] 3Un altro comando, cioè la funzione summary(), ci permette di ottenere un po’ di informazioni statistiche.
> summary(samples)
Min. 1st Qu. Median Mean 3rd Qu. Max.
3.00 36.25 71.00 61.17 91.75 100.00e la funzione plot() di porre gli elementi su un grafico
plot(samples)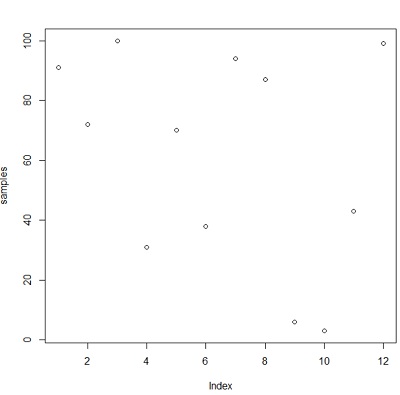
Matrici
Definiti gli array, adesso il passo successivo è quello delle matrici. Per definire una matrice è possibile partire da un array come quelli visti in precedenza. Prendiamo per esempio samples. Assegnamolo ad una variabile M che useremo per la matrice.
M <- samples
> M
[1] 91 72 100 31 70 38 94 87 6 3 43 99Adesso i successivi passi saranno quelli di convertire un array in una matrice. L’array è di 12 elementi che possono essere convertiti per esempio in una matrice 4×3. Per cambiare quindi la dimensione dell’array, si può definire direttamente la funzione dim().
dim(M) <- c(3,4)
> M
[,1] [,2] [,3] [,4]
[1,] 91 31 94 3
[2,] 72 70 87 43
[3,] 100 38 6 99Come possiamo vedere, per convertire un array in una matrice è sufficiente variarne le dimensioni. Un altro modo per creare o modificare una matrice è tramite la funzione fix() che apre un editor che ci permette di poter visualizzare la matrice e variarne i valori.
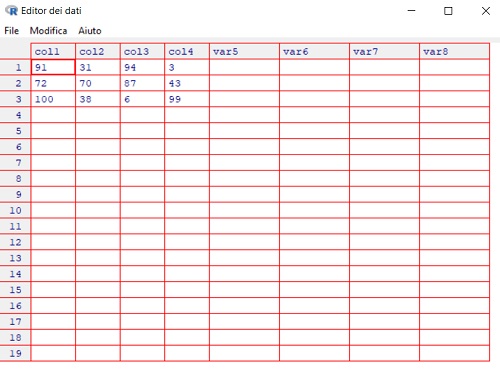
Un’operazione molto comune che si effettua con le matrici è la trasposizione, questa è possibile tramite la semplice funzione t().
> t(M)
[,1] [,2] [,3]
col1 91 72 100
col2 31 70 38
col3 94 87 6
col4 3 43 99Le Liste
Gli oggetti visti finora avevano la caratteristica di poter contenere solo elementi con valori dello stesso tipo. Le liste permettono invece di poter raggruppare contenuti di diverso tipo. Per creare una lista si usa la funzione list() con gli elementi al suo interno passati come parametri.
> t <- "word"
> a <- 5
> M <- sample(1:100, 12, replace=T)
> dim(M) <- c(3,4)
> mylist <- list(M,a,t)
> mylist
[[1]]
[,1] [,2] [,3] [,4]
[1,] 91 35 6 33
[2,] 13 91 21 71
[3,] 67 27 31 30
[[2]]
[1] 5
[[3]]
[1] "word"Per accedere agli elementi della lista è sufficiente indicare il nome della lista con l’indice dell’elemento desiderato. Gli indici partono dal valore 1.
> mylist[1]
[[1]]
[,1] [,2] [,3] [,4]
[1,] 91 35 6 33
[2,] 13 91 21 71
[3,] 67 27 31 30Dataframe
La tipologia di dato più interessante per lavorare con i dati ed utilizzare R come strumento di elaborazioni ed analisi statistiche e di dati, è il dataframe. Il dataframe è praticamente una tabella dati con le intestazioni di colonne e gli indici di riga.
> a <- c(1,4,3,3,5)
> b <- c("BMW","Ford","Opel","Fiat","Alfa Romeo")
> c <- c(TRUE,TRUE,FALSE,FALSE,FALSE)
> df <- data.frame(a,b,c)
> df
a b c
1 1 BMW TRUE
2 4 Ford TRUE
3 3 Opel FALSE
4 3 Fiat FALSE
5 5 Alfa Romeo FALSEPer accedere agli elementi di una colonna del dataframe
> df$a
[1] 1 4 3 3 5Per accedere agli elementi di una riga del dataframe
> df[,2]
[1] "BMW" "Ford" "Opel" "Fiat" "Alfa Romeo"Le funzioni
I comandi e le funzioni presenti all’interno di R sono moltissime, ma non possono coprire certamente sempre il necessario. Inoltre spesso una serie di istruzioni, comandi e funzioni possono essere racchiuse in una singola operazione, che la definiremo come una specifica funzione.
Creiamo per esempio una funzione calcola l’area del cerchio dato il raggio che chiameremo CircleArea. Per definire questa funzione:
> CircleArea <- function(radius){
+ radius*radius*pi
+ }
Adesso che la funzione è definita la potremo richiamare ogni volta che ci serve nel seguente modo.
> CircleArea(12)
[1] 452.3893