
Random Forest è un algoritmo di apprendimento automatico che si basa sulla creazione di un insieme di alberi decisionali. Ogni albero viene creato utilizzando un subset casuale dei dati di addestramento e produce una previsione. Alla fine, le previsioni di tutti gli alberi vengono combinate attraverso il voto della maggioranza per ottenere la previsione finale.
[wpda_org_chart tree_id=21 theme_id=50]
L’algoritmo Random Forest
L’algoritmo Random Forest è una tecnica di apprendimento automatico che appartiene alla categoria degli ensemble methods, ovvero metodi che combinano più modelli più deboli per creare un modello più forte e robusto. L’idea alla base del Random Forest è di creare un insieme (ensemble) di alberi decisionali, ognuno costruito su un diverso subset dei dati e con un certo grado di casualità nell’addestramento. Le previsioni di ciascun albero vengono combinate attraverso il voto della maggioranza (nel caso della classificazione) o attraverso la media (nel caso della regressione) per ottenere la previsione finale.
Ecco come funziona l’algoritmo Random Forest:
- Bagging (Bootstrap Aggregating): L’ensemble Random Forest inizia creando diversi subset dei dati di addestramento. Questi subset sono creati utilizzando un campionamento con sostituzione dai dati originali. Questo processo è noto come bagging. Ogni subset rappresenta un set di addestramento unico per un singolo albero.
- Creazione degli Alberi: Per ogni subset di dati, viene creato un albero decisionale. Ogni albero viene addestrato utilizzando solo un subset dei dati, ma può avere delle differenze a livello di strutture e delle suddivisioni dei nodi a causa del campionamento casuale.
- Voto della Maggioranza: Una volta che tutti gli alberi sono stati addestrati, le previsioni di ciascun albero vengono combinate. Nel caso della classificazione, si prende in considerazione la classe predetta dalla maggioranza degli alberi (voto della maggioranza). Nel caso della regressione, si calcola la media delle previsioni di tutti gli alberi.
- Riduzione dell’Overfitting: L’uso di diversi subset di dati e la casualità introdotta durante la creazione degli alberi aiutano a ridurre l’overfitting, che è una problematica comune negli alberi decisionali singoli.
Random Forest ha diversi vantaggi, tra cui:
- Migliora la generalizzazione su nuovi dati grazie alla riduzione dell’overfitting.
- È resistente al rumore e ai valori atipici nei dati.
- Non richiede particolari preparazioni dei dati.
- Può gestire sia dati categorici che numerici.
Un po’ di storia
L’algoritmo Random Forest è stato introdotto da Leo Breiman nel 2001. Breiman era un influente statistico e professore presso l’Università della California, Berkeley. L’articolo originale di Leo Breiman, intitolato “Random Forests,” è stato pubblicato nel giornale Machine Learning nel 2001. L’articolo ha presentato l’idea di creare un ensemble di alberi decisionali con l’obiettivo di migliorare le prestazioni di previsione e la robustezza rispetto ai singoli alberi.
La motivazione principale alla base della creazione di Random Forest era affrontare le limitazioni e le debolezze degli alberi decisionali singoli. Gli alberi decisionali possono essere propensi all’overfitting, specialmente quando sono profondi e complessi, e possono essere sensibili ai piccoli cambiamenti nei dati. L’obiettivo di Breiman era quello di sviluppare un approccio che potesse migliorare la generalizzazione, ridurre l’overfitting e rendere il processo di apprendimento automatico più robusto.
La chiave dell’efficacia di Random Forest risiede nell’idea di creare diversi alberi decisionali su subset casuali dei dati e combinare le loro previsioni. Questo processo di aggregazione delle previsioni riduce la varianza e migliora la stabilità delle previsioni complessive.
Da quando è stato introdotto, Random Forest è diventato uno dei modelli di apprendimento automatico più popolari e ampiamente utilizzati. È adatto a una vasta gamma di problemi di classificazione e regressione e ha dimostrato di ottenere ottime prestazioni in molte applicazioni. La sua flessibilità, robustezza e capacità di gestire dati eterogenei lo hanno reso uno strumento fondamentale per molti data scientist e ricercatori nel campo dell’apprendimento automatico.

Se vuoi approfondire l’argomento e scoprire di più sul mondo della Data Science con Python, ti consiglio di leggere il mio libro:
Fabio Nelli
Random Forest con la libreria scikit-learn
In Python, puoi utilizzare la libreria scikit-learn per implementare l’algoritmo Random Forest e creare modelli basati su Random Forest. Questo algoritmo può essere utilizzato per due diversi approcci del Machine Learning.
- Classificazione
- Regressione
La Classificazion con Random Forest
La Classification Random Forest è una variante dell’algoritmo Random Forest utilizzata per risolvere problemi di classificazione. L’obiettivo della Classification Random Forest è prevedere a quale classe appartiene un’istanza di input.
Ecco come puoi utilizzare la Classification Random Forest con la libreria scikit-learn in Python:
- Importa le librerie:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score- Carica il dataset e dividi i dati:
# Carica il dataset Iris come esempio
iris = load_iris()
X = iris.data
y = iris.target
# Dividi il dataset in set di addestramento e di test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)- Crea e addestra il classificatore Random Forest:
# Crea il classificatore Random Forest con 100 alberi
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# Addestra il classificatore sul set di addestramento
clf.fit(X_train, y_train)- Effettua previsioni e calcola l’accuratezza:
# Effettua previsioni sul set di test
predictions = clf.predict(X_test)
# Calcola l'accuratezza delle previsioni
accuracy = accuracy_score(y_test, predictions)
print("Accuracy:", accuracy)In questo esempio, stiamo utilizzando il dataset Iris per creare un classificatore Random Forest. Dopo aver diviso il dataset in set di addestramento e di test, creiamo un oggetto RandomForestClassifier con 100 alberi (n_estimators=100). Poi addestriamo il classificatore sui dati di addestramento e facciamo previsioni sul set di test. L’accuratezza delle previsioni viene calcolata utilizzando la funzione accuracy_score. Eseguendo si ottiene il valore dell’accuratezza.
Accuracy: 1.0Per ulteriori descrizioni della validità del modello appena istruito, possiamo aggiungere ulteriori rappresentazioni grafiche utili, come anche la matrice di confusione.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix
import seaborn as sns
# Visualizza l'importanza delle feature
feature_importances = clf.feature_importances_
feature_names = iris.feature_names
plt.barh(range(len(feature_importances)), feature_importances, align='center')
plt.yticks(np.arange(len(feature_names)), feature_names)
plt.xlabel('Importanza delle Feature')
plt.title('Importanza delle Feature nel Random Forest')
plt.show()
# Visualizza la matrice di confusione
cm = confusion_matrix(y_test, predictions)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues', xticklabels=iris.target_names, yticklabels=iris.target_names)
plt.xlabel('Previsioni')
plt.ylabel('Valori Veri')
plt.title('Matrice di Confusione del Random Forest')
plt.show()Eseguendo anche questa parte di codice otterremo le due seguenti visualizzazioni. Dapprima un diagramma che rappresenti l’importanza delle feature alla validità delle previsioni del modello: un grafico a barre orizzontale che mostra l’importanza relativa di ciascuna feature nel modello Random Forest. Questo può darti un’idea di quali feature sono più influenti nel processo decisionale del modello.

E poi la matrice di confusione dei risultati di previsione ottenuti dal nostro modello. Una matrice di confusione è una rappresentazione visiva delle prestazioni del modello. Mostra quanti campioni sono stati classificati correttamente e quanti in modo errato per ciascuna classe. In questo caso, le classi corrispondono ai tipi di iris nel dataset.
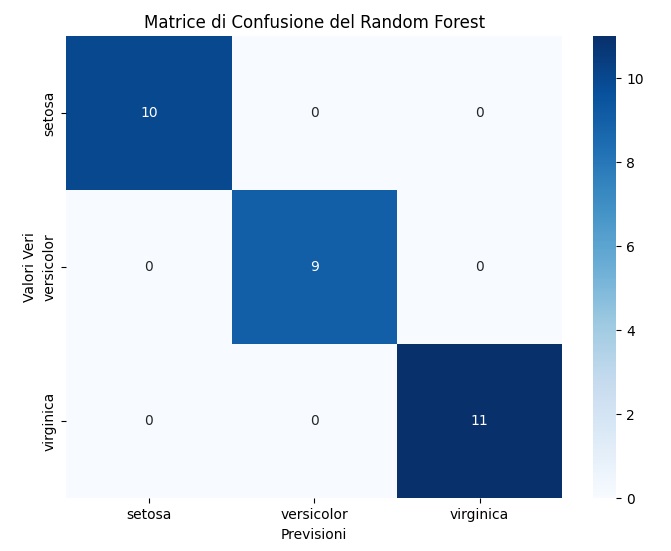
Ricorda che è importante regolare gli iperparametri dell’algoritmo, come il numero di alberi, la profondità massima degli alberi e il numero massimo di attributi da considerare per la divisione (max_features), per ottenere i migliori risultati sulla tua sfida di classificazione specifica.

Libro Suggerito
Se sei interessato al Machine Learning e ti piace programmare in Python ti suggerisco di leggere questo libro:
La Regressione con Random Forest
La Regression Random Forest è una variante dell’algoritmo Random Forest che è utilizzata per problemi di regressione anziché di classificazione. Mentre l’algoritmo Random Forest standard è spesso utilizzato per problemi di classificazione in cui l’obiettivo è prevedere una classe o una categoria, la Regression Random Forest è utilizzata per prevedere valori numerici continui.
La Regression Random Forest funziona in modo simile alla versione di classificazione, ma con alcune differenze nell’output e nel processo di aggregazione delle previsioni:
- Creazione degli alberi: Come nella Random Forest per la classificazione, vengono creati diversi alberi decisionali utilizzando subset casuali dei dati di addestramento. Ogni albero viene addestrato per prevedere un valore numerico anziché una classe.
- Previsioni degli alberi: Dopo aver creato gli alberi, ogni albero esegue previsioni sui dati di test. In questo caso, le previsioni saranno valori numerici.
- Aggregazione delle previsioni: Le previsioni di ogni albero vengono combinate per ottenere la previsione finale. Invece di utilizzare il voto della maggioranza come nella classificazione, viene utiliata la media delle previsioni di tutti gli alberi. Quindi, la previsione finale è la media delle previsioni dei singoli alberi.
L’obiettivo della Regression Random Forest è prevedere un valore numerico continuo che rappresenta una caratteristica di output del problema. Ad esempio, potrebbe essere utilizzata per prevedere il prezzo di una casa in base alle sue caratteristiche, la quantità di vendite in base a variabili di marketing o qualsiasi altro problema in cui la variabile di output sia un valore numerico.
In Python, puoi utilizzare la stessa libreria scikit-learn per implementare la Regression Random Forest utilizzando la classe RandomForestRegressor.
Ecco come puoi utilizzare la Regression Random Forest con la libreria scikit-learn in Python:
- Importa le librerie:
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error- Carica il dataset e dividi i dati:
# Carica il dataset California Housing come esempio
housing = fetch_california_housing()
X = housing.data
y = housing.target
# Dividi il dataset in set di addestramento e di test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)- Crea e addestra il regressore Random Forest:
# Crea il regressore Random Forest con 100 alberi
reg = RandomForestRegressor(n_estimators=100, random_state=42)
# Addestra il regressore sul set di addestramento
reg.fit(X_train, y_train)- Effettua previsioni e calcola l’errore medio quadratico:
# Effettua previsioni sul set di test
predictions = reg.predict(X_test)
# Calcola l'errore medio quadratico delle previsioni
mse = mean_squared_error(y_test, predictions)
print("Mean Squared Error:", mse)In questo esempio, stiamo utilizzando il dataset Boston House Prices per creare un regressore Random Forest. Dopo aver diviso il dataset in set di addestramento e di test, creiamo un oggetto RandomForestRegressor con 100 alberi (n_estimators=100). Poi addestriamo il regressore sui dati di addestramento e facciamo previsioni sul set di test. L’errore medio quadratico (MSE) delle previsioni viene calcolato utilizzando la funzione mean_squared_error. Eseguendo si otterrà il valore della MSE.
Mean Squared Error: 0.2553684927247781Anche in questo caso è possibile aggiungere delle visualizzazioni che possano aiutarci a comprendere meglio la validità o meno del modello di regressione del Random Forest.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Grafico di dispersione tra valori effettivi e previsti
plt.scatter(y_test, predictions)
plt.xlabel('Valori Effettivi')
plt.ylabel('Previsioni')
plt.title('Confronto tra Valori Effettivi e Previsioni')
plt.show()
# Visualizza l'importanza delle feature
feature_importances = reg.feature_importances_
feature_names = housing.feature_names
plt.barh(range(len(feature_importances)), feature_importances, align='center')
plt.yticks(np.arange(len(feature_names)), feature_names)
plt.xlabel('Importanza delle Feature')
plt.title('Importanza delle Feature nel Random Forest per la Regressione')
plt.show()
# Visualizza la distribuzione degli errori
errors = y_test - predictions
sns.histplot(errors, kde=True)
plt.xlabel('Errori')
plt.ylabel('Frequenza')
plt.title('Distribuzione degli Errori nella Regressione con Random Forest')
plt.show()
Eseguendo il codice si ottengono tre diverse visualizzazioni. La prima visualizzazione è un Grafico di Dispersione. Un grafico di dispersione che mostra la relazione tra i valori effettivi e le previsioni del modello. Idealmente, i punti dovrebbero allinearsi con la linea diagonale, indicando una buona previsione.

Importanza delle Feature: Un grafico a barre orizzontale che mostra l’importanza relativa di ciascuna feature nel modello Random Forest per la regressione.
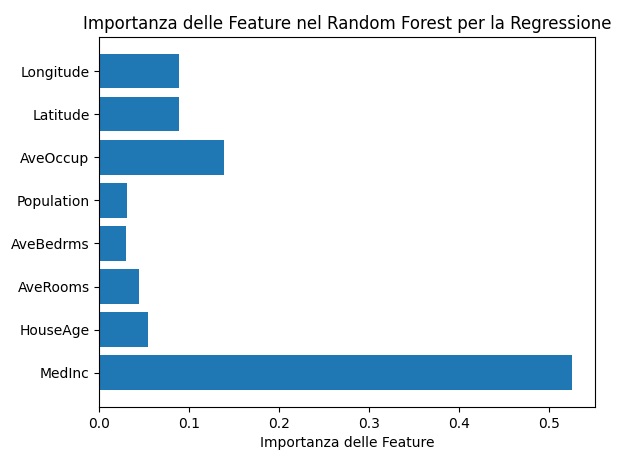
Distribuzione degli Errori: Un istogramma che mostra la distribuzione degli errori, aiutandoti a comprendere la precisione del modello nelle diverse predizioni.
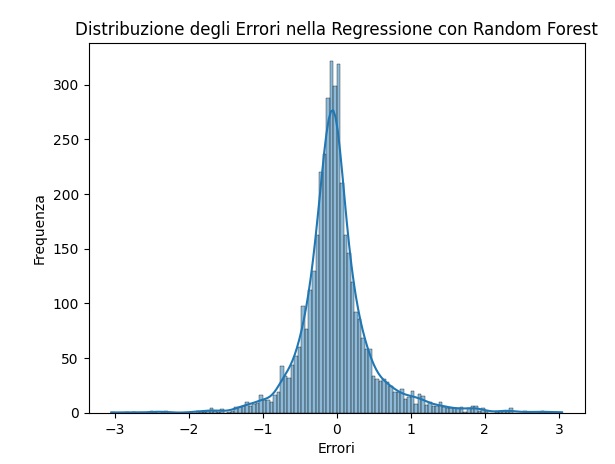
Come sempre, è importante regolare gli iperparametri dell’algoritmo per ottenere i migliori risultati sulla tua sfida di regressione specifica. Puoi esplorare vari valori per gli iperparametri come il numero di alberi, la profondità massima degli alberi e il numero massimo di attributi da considerare per la divisione (max_features).

Libro Suggerito:
Se sei interessato all’argomento, ti suggerisco di leggere questo libro:
Alcuni dataset per esercitarsi nei problemi di classificazione con scikit-learn
Se si vuole fare un po’ di pratica di Machine Learning lavorando con problemi di classificazione esistono dei dataset già pronti su cui esercitarsi. Ecco alcuni dataset che puoi utilizzare per esempi pratici con la Classification Random Forest utilizzando scikit-learn senza utilizzare il dataset Iris:
- Breast Cancer Wisconsin (Diagnostic) Dataset: Questo dataset contiene caratteristiche estratte da immagini di aspirati sottili di noduli al seno e l’obiettivo è classificare se un tumore è benigno o maligno.
- Carica il dataset:
from sklearn.datasets import load_breast_cancer
- Carica il dataset:
- Wine Dataset: Questo dataset contiene misurazioni chimiche di vini provenienti da tre diverse varietà. L’obiettivo è classificare la varietà del vino.
- Carica il dataset:
from sklearn.datasets import load_wine
- Carica il dataset:
- Digits Dataset: Questo dataset contiene immagini di cifre scritte a mano e l’obiettivo è classificare quale cifra è rappresentata.
- Carica il dataset:
from sklearn.datasets import load_digits
- Carica il dataset:
- Heart Disease UCI Dataset: Questo dataset contiene informazioni cliniche per pazienti e l’obiettivo è classificare se un paziente ha o non ha una malattia cardiaca.
- Carica il dataset: Puoi scaricare il dataset da UCI Machine Learning Repository
- Bank Marketing Dataset: Questo dataset contiene informazioni su campagne di marketing bancario e l’obiettivo è classificare se un cliente sottoscriverà o meno un deposito a termine.
- Carica il dataset: Puoi scaricare il dataset da UCI Machine Learning Repository
- Titanic Dataset: Questo dataset contiene informazioni sui passeggeri del Titanic e l’obiettivo è classificare se un passeggero sopravvivrà o meno.
- Carica il dataset: Puoi scaricare il dataset da Kaggle
Per utilizzare uno di questi dataset, puoi importare il dataset appropriato utilizzando la funzione load_* fornita da sklearn.datasets. Assicurati di leggere la documentazione associata al dataset per capire le caratteristiche, la variabile di output e come preparare i dati per l’addestramento del modello Random Forest.
Alcuni dataset per esercitarsi nei problemi di regressione con scikit-learn
Ecco alcuni dataset che puoi utilizzare per esempi pratici con la Regression Random Forest utilizzando scikit-learn:
- California Housing Dataset: Questo dataset contiene dati immobiliari in California e l’obiettivo è prevedere il valore mediano delle abitazioni in diverse aree,
- Carica il dataset:
from sklearn.datasets import fetch_california_housing
- Carica il dataset:
- Diabetes Dataset: Questo dataset contiene misurazioni mediche correlate al diabete e l’obiettivo è prevedere la progressione della malattia un anno dopo.
- Carica il dataset:
from sklearn.datasets import load_diabetes
- Carica il dataset:
- Energy Efficiency Dataset: Questo dataset contiene informazioni sulla prestazione energetica degli edifici e l’obiettivo è prevedere l’efficienza energetica.
- Carica il dataset: Puoi scaricare il dataset da UCI Machine Learning Repository
- Concrete Compressive Strength Dataset: Questo dataset contiene dati sulla resistenza alla compressione del calcestruzzo e l’obiettivo è prevedere la resistenza alla compressione.
- Carica il dataset: Puoi scaricare il dataset da UCI Machine Learning Repository
- Combined Cycle Power Plant Dataset: Questo dataset contiene dati sulla produzione di energia in una centrale elettrica e l’obiettivo è prevedere l’efficienza energetica.
- Carica il dataset: Puoi scaricare il dataset da UCI Machine Learning Repository
Per utilizzare uno di questi dataset, puoi importare il dataset appropriato utilizzando la funzione load_* fornita da sklearn.datasets. Assicurati di leggere la documentazione associata al dataset per capire le caratteristiche, la variabile di output e come preparare i dati per l’addestramento del modello Regression Random Forest.